Linux/Unix系统编程手册-笔记4.深入探究文件I/O
Contents
原子操作与竞争条件
创建文件
当同时指定O_EXCL和O_CREAT作为open()的标志位时,如果要打开文件已然存在,open()将返回一个错误。这提供了一种机制,保证进程是打开文件的创建者。否则当open()失败时,再次使用O_CREAT标志调用open()创建文件的过程中可能有另一个进程或线程已经创建了同名文件,因为无论文件存在与否,第二次调用open()总会成功。使用O_EXCL和O_CREAT标志来一次性的调用open()可以避免这种情况,因为其确保检查文件和创建文件属于一个单一的原子操作。
向文件尾部追加数据
多个进程向同一个文件尾部添加数据也会出现竞争状态,要规避这一问题,需要将文件偏移量移动和数据写操作纳入同一原子操作。在打开文件时加入O_APPEND标志就可以保证这一点。
文件控制操作: fcntl()
fcntl()系统调用对一个打开的文件描述符执行一系列控制操作。
比如获取文件访问模式和状态标志
| |
判断文件访问模式:O_RDONLY(0),O_WRONLY(1),O_RDWR(2)
| |
可以使用fcntl()的F_SETFL命令来修改打开文件的某些状态标志。允许修改的标志有O_APPEND、O_NONBLOCK、O_NOATIME、O_ASYNC和O_DIRECT。系统将忽略其他标志的修改。修改文件状态标志可以先使用fcntl的F_GETFL命令,来获取当前标志的副本,然后修改需要变更的标志位,再通过F_SETFL命令更新状态标志。
| |
文件描述符和打开文件之间的关系
理清这之中的关系需要了解由内核维护的3个数据结构。
- 进程级的文件描述符表
- 系统级的打开文件表
- 文件系统的i-node表
对于每个进程有文件描述符(open file descriptor)表。该表的每一条目都记录了单个文件描述符的相关信息。
- 控制文件描述符操作的一组标志,(目前只定义了close-on-exec)
- 对打开文件句柄的引用。
内核对于所有打开的文件维护有一个系统级的描述表格,每个条目称为打开文件句柄(open file handle)。一个打开的文件句柄存储了与一个打开文件相关的全部信息:
- 当前文件偏移量
- 打开文件时的所用的状态标志
- 文件访问模式
- 与信号驱动I/O相关的设置
- 对该文件i-node对象的引用
- 文件类型和访问权限
- 一个指针,指向该文件所持有的锁的列表
- 文件的各种属性,包括文件大小以及不同类型操作相关的时间戳。
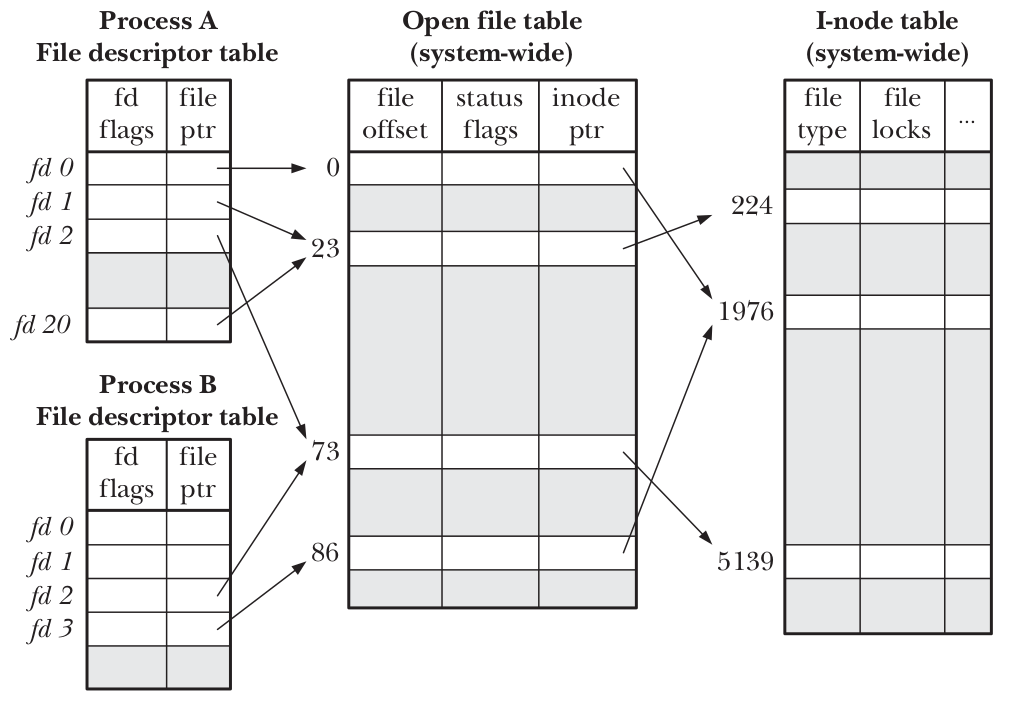
文件描述符、打开的文件句柄和i-node之间的关系
上图展示了这三个数据结构之间的关系
- 在进程A中,文件描述符1和20都指向同一个打开的文件句柄(23),这可能是dup()、dup2()或fcntl()而形成的。dup会创建一个文件描述符的copy,dup2功能类似,区别在于可以指定新的文件描述符而不是使用最小未用编号(之前提过,文件描述符是个小整数)。 如前文所述文件句柄中保存了当前文件偏移量,所以文件描述符指向同一文件句柄将共享文件偏移量,无论这两个文件描述符属于同一进程还是不同进程。同样的文件打开标志也保存在打开的文件句柄中,所以情况一样。(cose-on-exec标志为进程和文件描述符号私有)
- 进程A和B有文件描述符指向同一个打开的文件句柄,这种情形可能在fork之后出现(即A和B之间是父子关系)或者当某进程通过UNIX域套接字将一个打开的文件描述符传递给另一个进程时也会出现。
- 此外不同的文件句柄也可能指向i-node表中的同一个条目,发生中情况是因为每个进程各自对统一文件发起了open()调用。同一个进程两次打开同一文件,也会发生类似情况。
在文件特定偏移量处的I/O
pread()和pwrite()会在指定偏移量处I/O,且不会改变当前文件偏移量。多线程时进程下的所有线程共享同一文件描述符表,这意味着打开文件的偏移量也为所有线程共享。使用pread() 和pwrite()系统调用可以避免竞争状态。
| |
分散输入和集中输出
| |
readv()系统调用的功能是:从fd所指代的文件中读取一片连续的字节,然后将其散置在iov指定的缓冲区中。从iov[0]开始依次填满每个缓冲区。这个操作是原子的。
writev()系统调用的功能是:将iov所指定的所有缓冲区中的数据拼接(“集中”)起来,然后以连续的字节写入fd所指代的文件中。同样是原子操作。
linux 2.6.30提供了可以在指定偏移量处执行分散输入/集中输出的系统调用preadv()和pwrite()。
读写大文件
32位系统偏移量最大2^31-1,想要读写大文件有两种方式:
- 使用fopen64(), open64(), lseek64(), truncate64(), stat64(), mmap64(), setrlimit64()等函数,为了操作大文件还添加了两个新的数据结构stat64和off64_t
- 使用 _FILE_OFFSET_BITS宏
在编译的时候加选项
| |
或者在源文件中include头文件之前定义:
| |
创建临时文件
| |
参数template 类似于 “/tmp/exampleXXXXXX”,最后6个字符必须为XXXXXX,这6个字符将被替换,正是因为会替换字符,所以传入参数必须是字符数组而非字符串常量。
| |
tmpfile()函数会创建一个名称唯一的临时文件,并以只读方式打开。执行成功会返回一个文件流,关闭文件流后将自动删除临时文件。
Exercises
- O_APPEND
The file is opened in append mode. Before each write(2), the file offset is positioned at the end of the file, as if with lseek(2). - 验证代码如下:
| |
使用和不使用O_APPEND标志,得到的文件大小存在差异:
| |
原因是不加O_APPEND标志则操作lseek()和write()操作不是原子的。在进程1往当前文件偏移量写入时,另一个进程可能已经写入了大量数据,偏移量已经改变了,两个进程的写入数据存在重叠。所以得到的文件小于加了O_APPEND标志的文件。
- 例程:
| |
解释:fd1和fd2指向同一个打开的文件句柄,所以共享文件偏移量,fd3重新打开了文件,所以是一个单独的文件句柄,写入从文件头部开始。
7. 考虑原子性,writev()需要先分配一块大内存,将各数组copy过去后,调用一次write()写入文件。readv()按顺序读入即可。